在一个完整的ComfyUI工作流里,最基本就要包含这几个要素:
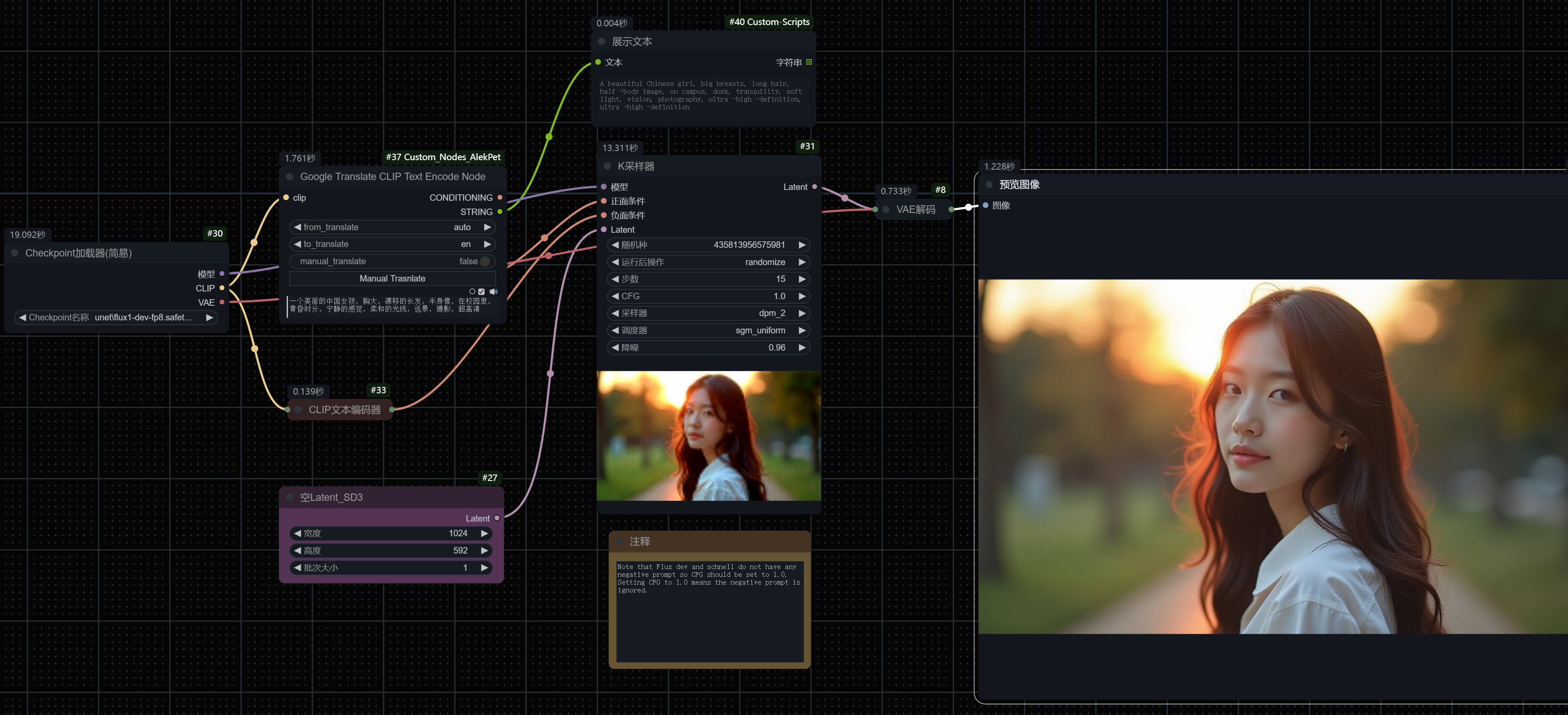
Checkpoint,相当于“导演”,每个不同的“导演”都会有不同的风格,有些模型是专门为真实人像设计的;而有些则是专门生成动画形式的。
CLIP文本编码器:这个是这部电影到底要拍什么的剧本。我们的Prompt提示词,就说明我们希望生成图片的关键要素。
Latent:潜空间,你可以认为是拍摄场地,就好像横店那样。这个拍摄场地有多大,也会定义好。
K采样器:就是拍摄团队,根据导演的指挥和剧本进行拍摄,最终生成一张图片所有的信息;
VAE解码:相当于后期团队,他们会把图片信息进行进一步处理,从而让我们能够看到最终的图像预览或者保存下载。
我们作为AI绘图的作者,可以选择导演,可以自己编写剧本,但最终能拍成什么样子,给拍摄团队最正确、最适合的指令,也是相当重要。
K采样器需要输入的信息是这样的:
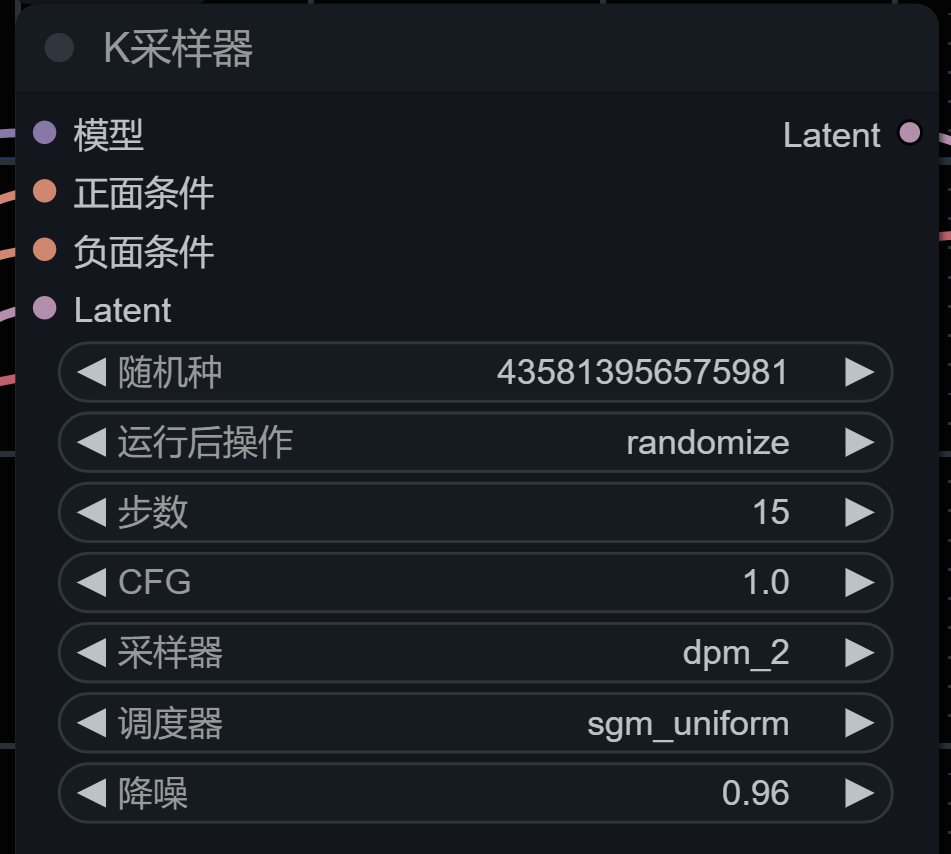
首先,随机种,可以理解为:在这次拍摄工作中,每生成一次图片,都会记录为一个种子Seed,它会有自己独一无二的数字。如果ComfyUI重启,那么这些Seed也同样会清空。
如果我们固定种子,那么输出的结果就是一样的,相当于调出之前生成过的那一张图片。
你可以在启动系统后,手动把第一张图片的随机种设置为0,不过一般不需要做这样无聊的事儿。
运行后操作:就是生成一张图片后,种子数字怎么变化,一般默认是随机,也可以选择“固定”、“增加”和“减少”。
随机种和运行后操作,是K采样器里不算重要的参数决定,真正影响最终图片效果的,是从“步数”开始。
之后的截屏,都来自于B站这个关于K采样器的入门讲解:https://www.bilibili.com/video/BV1HFuWeGE7V?spm_id_from=333.788.videopod.sections&vd_source=7f7c432bb460688c136dc5650a53f034

步数越多,图像细节会越多,也更加清晰。
可是,我们也不可以无限制调高步数,因为随着步数增加,图片中也会出现更多我们觉得没用的细节,并且生成的速度也会越慢。
你可以想象为:拍摄团队对一个场景持续拍摄,拍摄时间越久,自然能抓捕到最合适的照片,但是消耗的时间和资源也会越久。在AI绘画里,步数太多,其实“油腻感”也会增加。
比方说,在同样的Prompt,以及K采样器设置相同的采样器和调度器,噪声也是一样的情况下,
步数设置10步,出现这样的照片:

步数设置15步,出现这样的照片:

步数设置25步,出现这样的照片:

步数为10的照片,清晰度就不是太好;步数15和步数25的照片差距其实已经不算很大,25的背景细节会更多一些,身体展示得也会更多。
我觉得以Flux 1 dev fp8模型来说,标准工作流的步数是设置在20,我觉得还是很合理的。
接下来来看下CFG值,这个参数是指生成的图片有多少权重听从Prompt,还是自由发挥。
在Flux 1 dev这个模型里,CFG默认是1,更改成其他数字则会生成失败。
而大部分模型,CFG会设置在7-8,这样能够平衡对Prompt的忠诚度和AI自由发挥。

我们再看降噪,这个数值介于0-1之间。
这个降噪,就好像是一块橡皮在擦一张脏脏照片的力度。那是不是就一定设置为1呢?其实也不是。
虽然降噪越接近于1,图片会越清晰,但也会因此失去一些细节。比方说,你看下面这比较图,在降噪是0.5时,天空中的云是非常丰富,但降噪到1,天空中云就很少,裙身上的花纹也消失不变,变得更加平滑了。
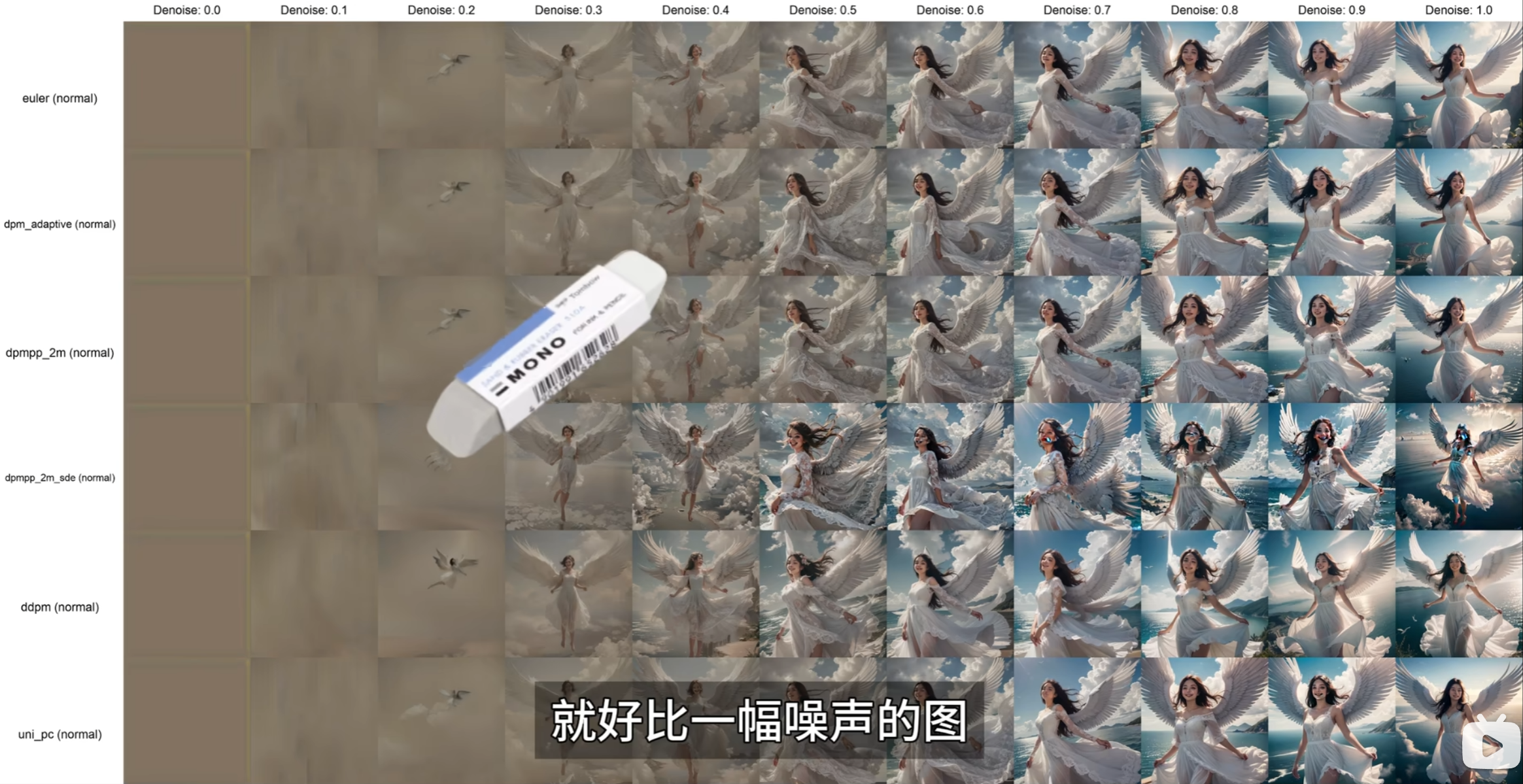
我用同样的参数和指令,唯独更改降噪。
当降噪为1时,图片是这样的:

降噪为0.8时,图片是这样的,很明显,背景的元素多了很多,但是照片看上去不是那么得“光滑”。

降噪设置在0.7时,图片已经算是生成失败了。再往下,Flux只能输出一张灰色噪声图片。

这就意味着,Flux 1 dev模型,最佳的降噪可能是0.9到1之间。
关于采样器,这个设置就比较复杂了。该B站视频作者给了这样的建议:

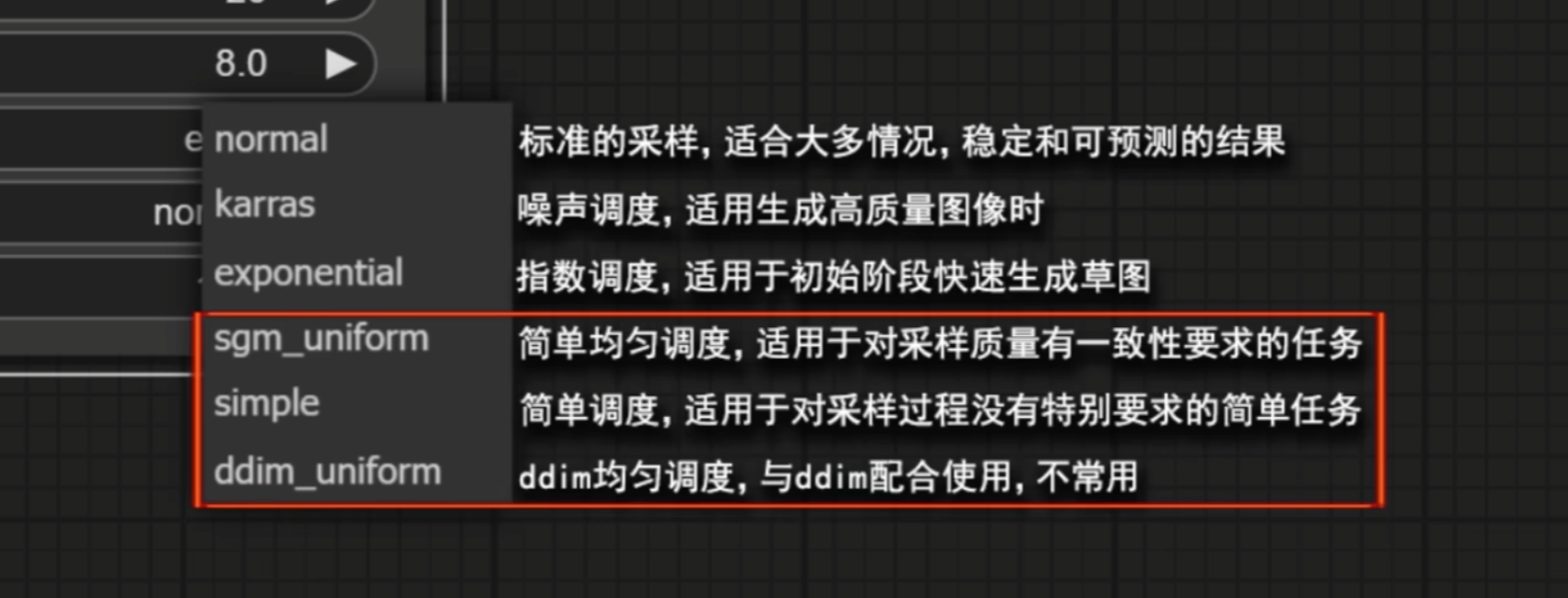
而调度器给的建议是这样的:

如果选择传统ODE模型,也就是Euler等,那么六种调度器都可以兼容。

如果选择DMP采样器,那么会建议选择Karras等四种采样器。我见到很多工作流演示里,都会选择DPMPP_2M+Karras这样的组合。我印象中最早就是在Nenly同学的B站里有提到。因为在WebUI里,这是个常见选择。

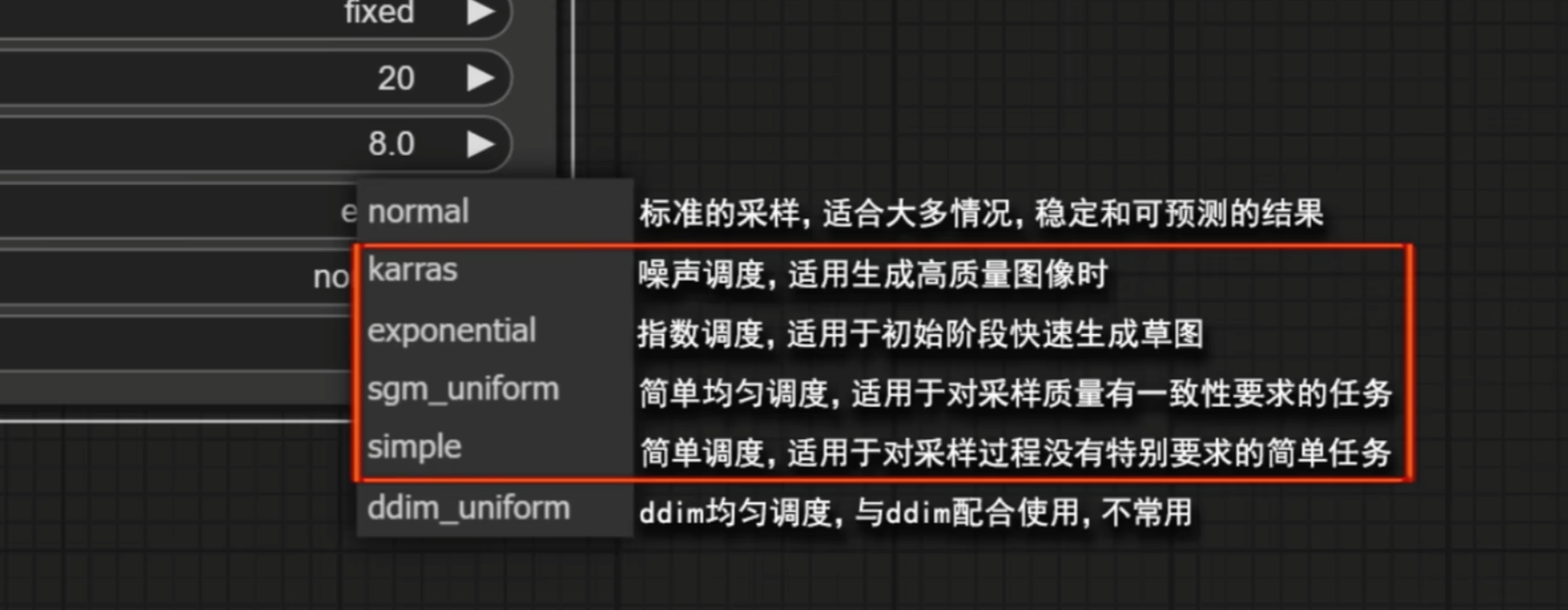
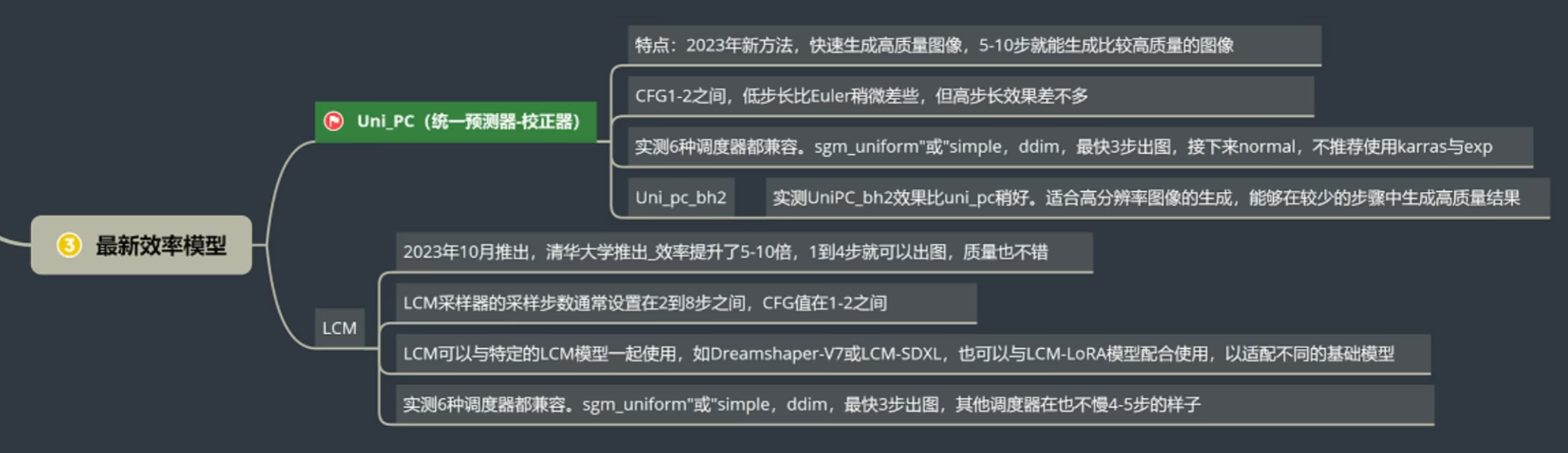
如果选择最新效率模型,比如Uni_PC等,那么调度器就建议用最后这三种。
对于Flux 1 Dev模型,网上有人给出这样的采样器和调度器的组合建议:
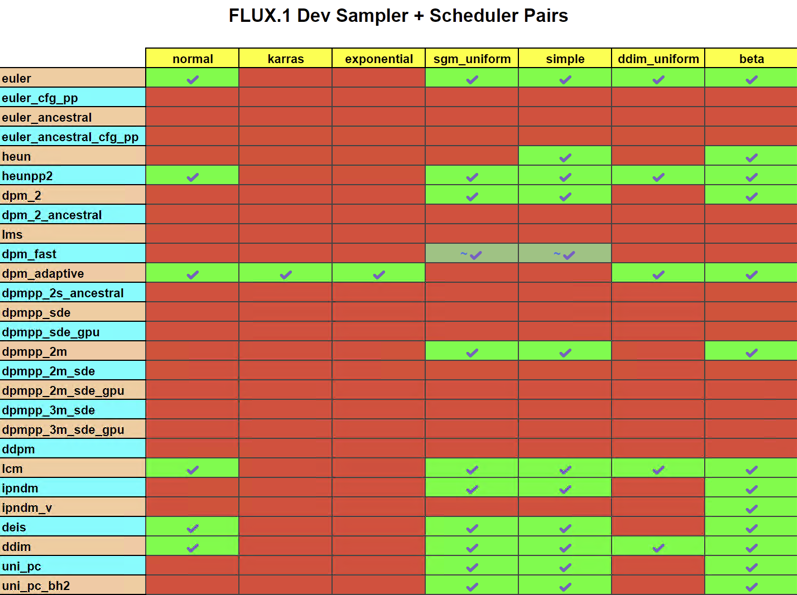
并且,uni_pc +beta:适用于平衡速度和质量,是大多数情况下的推荐选择。来源:https://aisc.chinaz.com/jiaocheng/10346.html



文章评论