关于如何安装ComfyUI,Nenly同学的视频以及网上可以找到一堆各种视频,又或者运用云平台本身就可以一键打开,这个咱们就不谈了。
我以咱们小白入门,生成第一张图开始。
我们首先要安装的,就是模型。我们先入门的自然是标准且目前最热门的大模型:Flux 1以及SD3.5。

Flux 1模型,是被称为能超越SD3的最好的AI绘画模型,在Nenly同学的课程视频里也有重点介绍。在SD3.5推出之后,这两个模型也算是各有千秋。你可以比较一下在同一个提示词下,这两个模型生成的图片差别——我个人更喜欢SD3.5的这张。
Flux 1模型目前最好的PRO版本并没有开源,免费使用的只有Flux 1 Dev模型,不过它对于显卡和内存的要求都比较高,所以大神们又再提炼了一个量化模型,Flux1-dev-fp8,这个模型在16-24GB显存就能通畅地运行。我的4090D显卡就是24GB。
什么叫量化模型?GPT 01 preview模型是这样解释的:
“量化版本”可以理解为把原本复杂、庞大的东西简化成更小、更高效的形式,但仍然保留主要功能。打个比方,就像把一本厚重的纸质书扫描成电子书。电子书占用的空间更小,方便携带,但内容还是一样的。
在计算机领域,特别是人工能中,模型通常非常大,占用大量的存储和计算资源。通过“量化”,我们将模型中的数字从高精度(比如32位)缩减到低精(比如8位)。这样,模型变得更小,运行速度更快,所需的资源也更少,同时还能保持较好的性能。这就像把高清的视频压成标准清晰度的视频,占用空间更小,播放更流畅,但画面质量可能稍有降低。
Flux-1-dev-fp8模型下载链接:https://huggingface.co/Kijai/flux-fp8/tree/main
除了模型之外,还需要有一个“工作流”,这个当然也可以是“抄作业”的。
我用了一个标准的Flux 1 Dev FP8的workflow,哪里找的我已经忘记了,附上链接:https://drive.wangchenjie.com/raw/ComfyUI/Flux%201%20dev%20fp8%20standard.json
这个工作流是我稍微更改后的,把原本输入Prompt的“CLIP文本编辑器”改成了“Google Translate CLIP Text Encode Node”这个自定义节点,用处是可以直接输入中文,通过Google Translate翻译成英文,这样就免去了我们还要另外找翻译软件的事儿——如果我们不太习惯写英文Prompt的话。
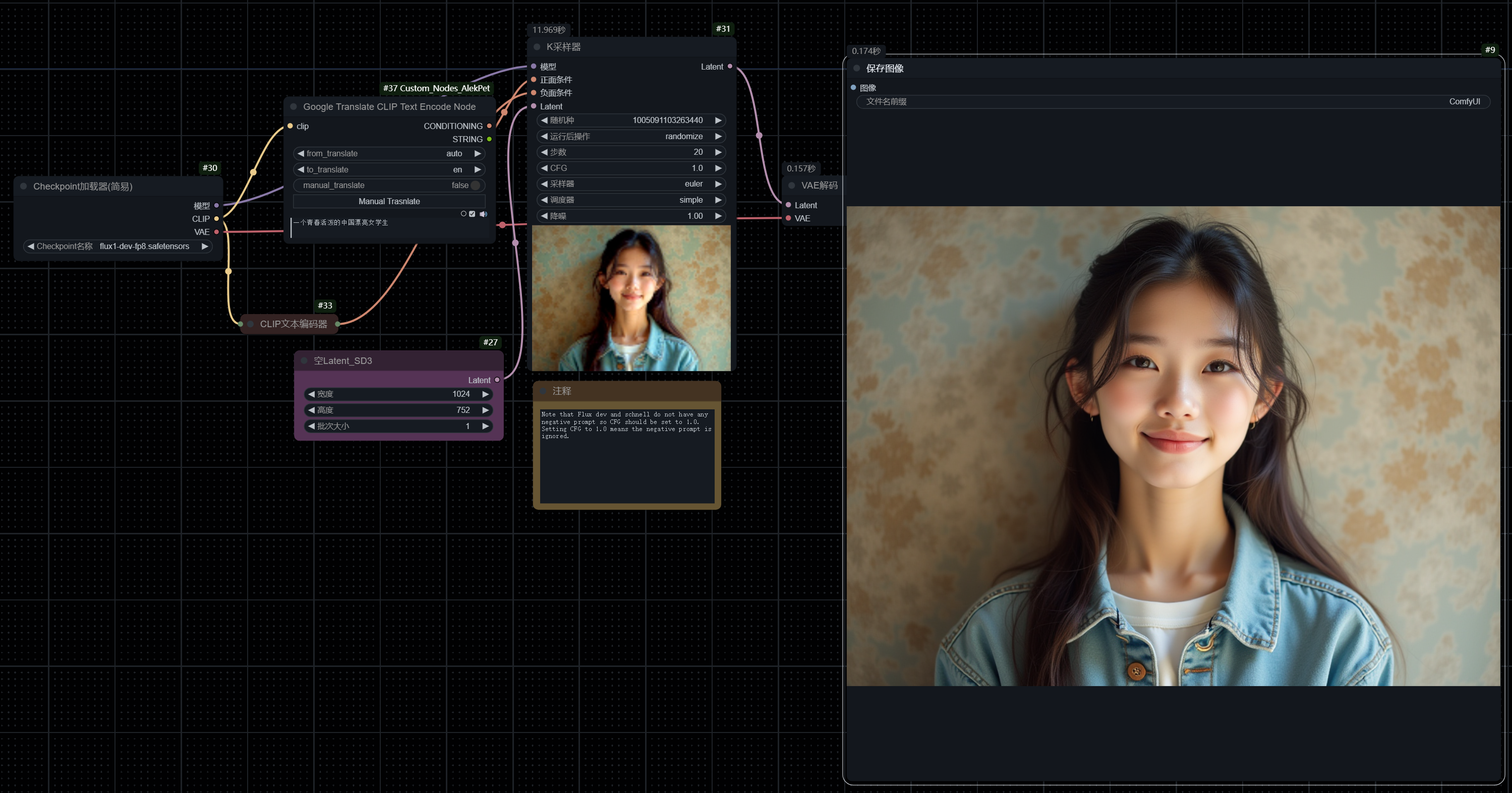
Flux 1 Dev fp8模型的文生图的工作流非常简单。
最左边“Checkpoint加载器”就是加载大模型,作为工作流的起点。
Checkpoint的“模型”端口会接到“K采样器”里面。大模型和采样器,是生成图片的关键。
在 AI 生成图片的过程中,K Sampling(K采样器) 就像是逐步使模糊的图像变得清晰的过程。想象你在看一张逐渐显现的照片,最初是一片模糊,然后逐步加上细节,最终呈现出完整的画面。K Sampling 就是这个一步步添加细节的过程。
它通过多次迭代,每次都对图像进行细微调整,就像画家在画布上从草图开始,逐层添加颜色和细节,最终完成一幅精美的作品。这个过程确保了最终生成的图片质量更高,更符合预期。简单来说,K Sampling 帮助 AI 从模糊到清晰,生成高质量的图片。
K采样器除了输入模型之外,还需要输入“正面条件”、“负面条件”以及“Latent”。正面条件就是希望图片中拥有的要素;负面条件就是不希望图片中出现的东西。因为很多大神自制的模型用了很多有水印的图片,所以常常在负面条件里,会输入“watermark”,还有“Easy Negative,worst quality,low quality,normal quality,lowers,monochrome,grayscales,skin spots,acnes,skin blemishes,age spot,6 more fingers on one hand,deformity,bad legs,error legs,bad feet,malformed limbs,extra limbs,ugly,poorly drawn hands,poorly drawn feet.poorly drawn face,text,mutilated,extra fingers,mutated hands,mutation,bad anatomy,cloned face,disfigured,fused fingers”等。
K采样器还有一个输入端口叫“Latent”。在 K Sampling 的过程中,"latent"(潜在表示)相当于图像的隐藏版本或骨架,包含了图像的核心信息和特征。你可以将其想象成建筑物的蓝图,虽然不是完整的建筑,但已经定义了建筑的结构和形状。
在这个过程中,AI 在潜在空间中对这些信息进行处理,就像建筑师根据蓝图一步步建造房屋一样。K Sampling 就是在这个潜在空间中,对这些核心信息进行逐步细化和完善的过程,最终生成完整的图像。
在实际操作中,Latent是接入一个“空Latent”的节点,里面可以输入需要生成图片的宽度、高度,以及批次大小,也就是一次生成几张图。
其他我们暂时就选择默认就行了。以后我们慢慢研究K采样器选择不同的参数会有什么不同的结果。
最后点击执行队列,就可以生成图片了。如果对于生成图片不满意,可以修改Prompt,或者再点击执行队列,反复生成到满意就行了。
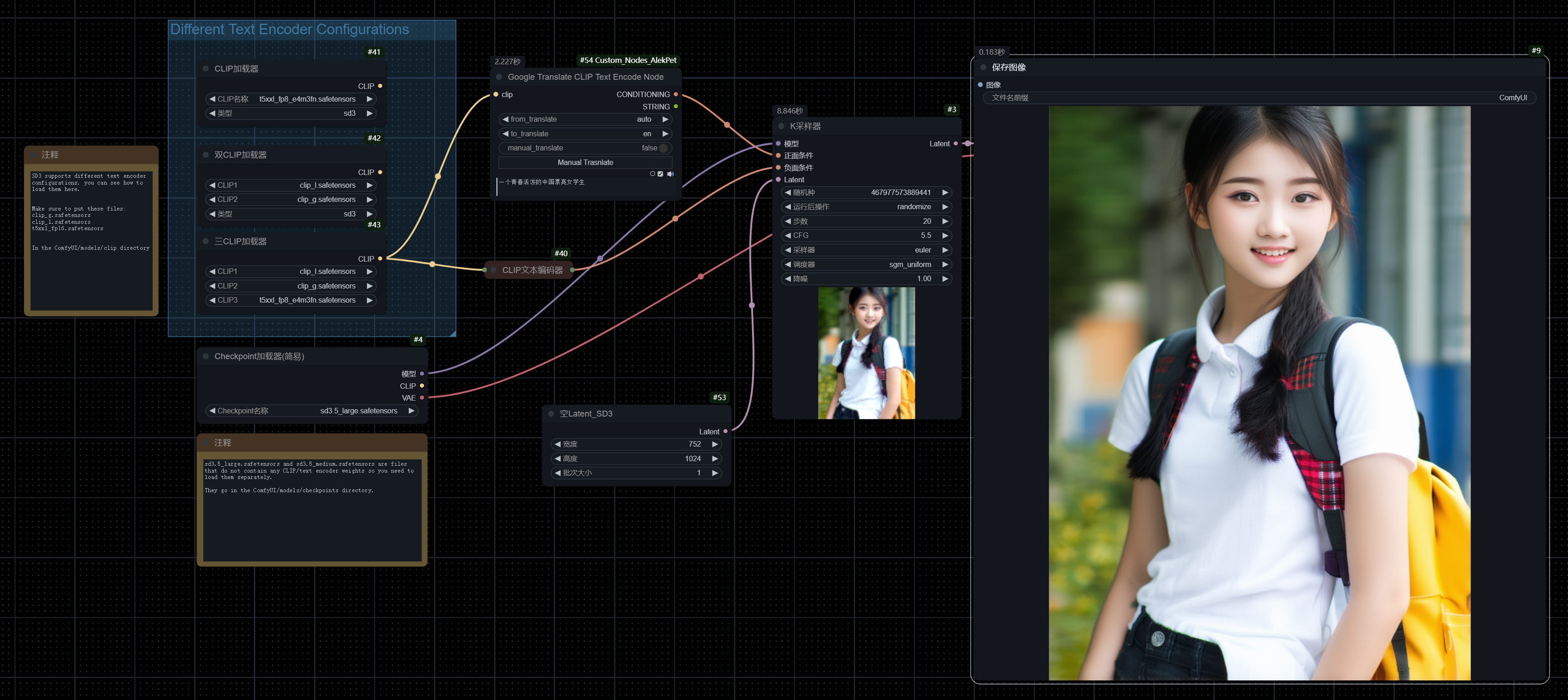
如果我们用的是SD3.5模型,那么工作流会多一个叫“Different Text Encoder Configurations”,标准工作流下载链接:https://drive.wangchenjie.com/raw/ComfyUI/SD3.5%20Standard.json
模型本身下载:https://huggingface.co/stabilityai/stable-diffusion-3.5-large/tree/main
在 SD3.5 模型中,之所以需要一个叫“三CLIP加载器”的组件,是为了强模型对文本描述的理解能力,从而生成更精确的图像。CLIP 模型就像 AI 的“语言翻译器”,将我们输入的文字转换成 AI 可以理解的形式。
使“三CLIP加载器”可以比喻成请了三个翻译官,每个人都有自己的理解方式。想象你向三位专家解释你的想法,每个人都给出自己的见解,然后你综合他们的意见,得到一个更全面、更准确的理解。这样,AI 就能从多个角度更深刻地理解你的描。
这三个Clip需要额外下载:https://huggingface.co/stabilityai/stable-diffusion-3.5-large/tree/main/text_encoders
如果内存是64G的话,就可以用t5xxl_fp16.safetensors;如果内存是32G的话,建议用text_encoders/t5xxl_fp8_e4m3fn.safetensors,作为Clip3。
至于这两个基础模型哪一个生成的效果更好,网上的测评也有很多。对于我们小白而言,把这两个模型都下载下来就对了,把模型文件放入相应的Model文件夹。
如果你和我一样,都能完成最基本的文生图的话,那么恭喜!你和我一样算是刚刚入门了吧!



文章评论